
Creating rawheaders for pyNetflix
-
In order to successfully scrape Netflix you will need to provide the same headers they use to make requests to their back end API. In our experience this is fairly easy using the inspect capability on Firefox.
Step 1. Open Firefox and Login to Netflix, double click and choose
Inspect Element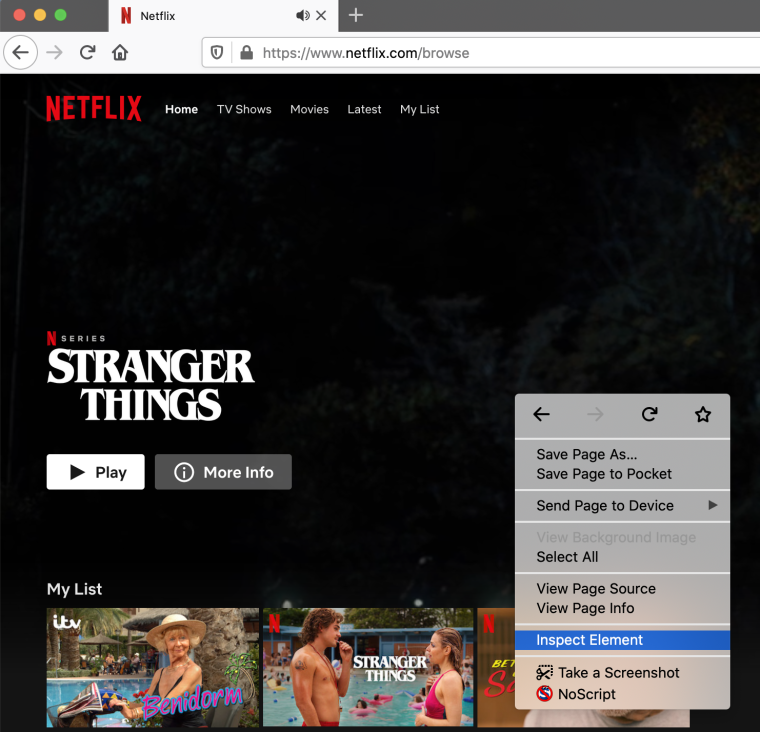
Step 2. On the inspect window choose the Network Tab and type "path" in the search field
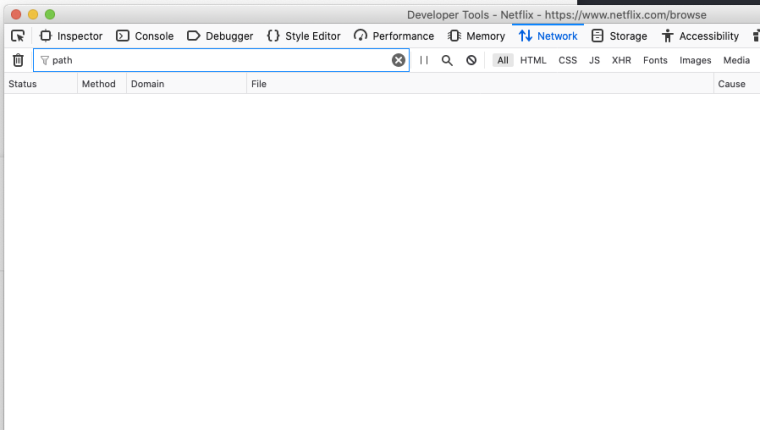
Step 3. Now go back to your Netflix window and start typing anything in the Netflix search window (next to Magnifying glass at the top). Back in the inspect window you should start seeing a bunch of requests going out to a
pathEvalutatorendpoint.
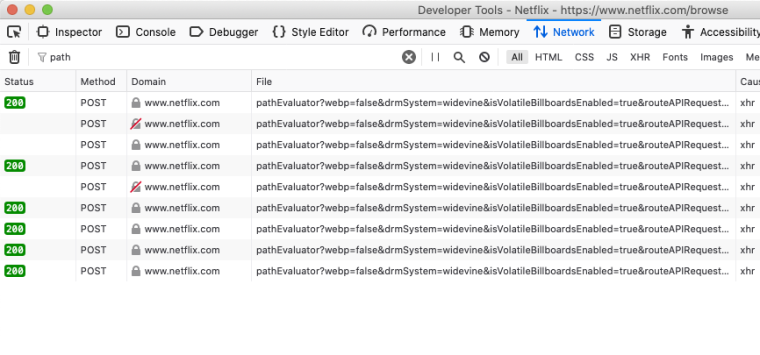
Step 4. Click on any of these and you will see a window appear with a bunch of tabs. It should default to the 'Headers' tab. Scroll down here until you see 'Request Headers'. Now click on the 'Raw Headers' to the right of 'Request Headers'.
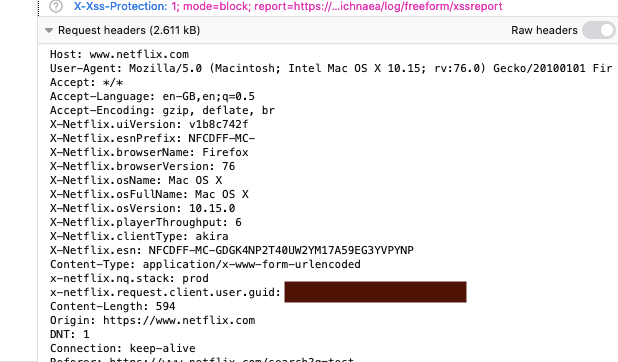
Step 5. Copy and paste everything in this box from Host to Cookie. Its sometimes tricky to get it into your clipboard. I have found it simplest to highlight everything and then double click (2 finger tap), it should give you the option to copy. Now paste this all in a file called
rawheadersin your pyNetflix directory.Step 6. Remember the url starting with 'pathEvaluator' you clicked on before? Copy that entire url. This is the endpoint Netflix posts its data to. Paste this in your config.py file
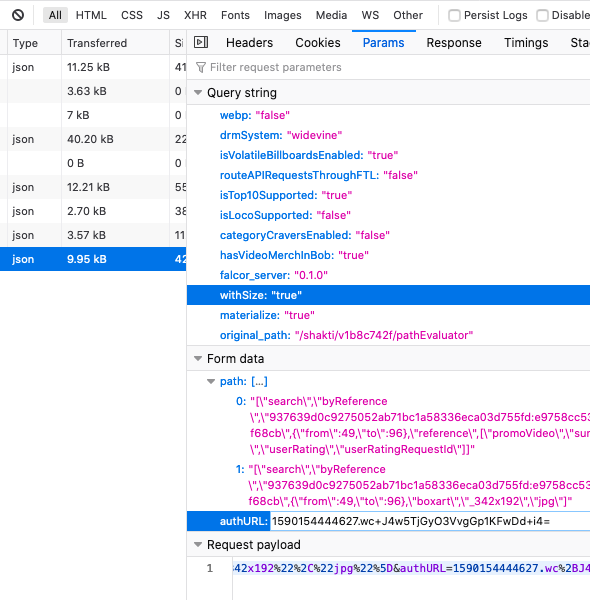
Step 7. Click on the 'Params' tab (2 to the right of 'Headers), Find a box called 'Form data', in here you should see a parameter called authURL. Copy contents of this for your config.py file.
Thats it, with this information you should be able to get to scraping data.
Please email us if you have any issues.
admin@unogs.com -
Will check it out! Thanks
-
BTW, there's no config.py in https://github.com/vbadita/pynetflix. What am I missing?
-
thats because ours is in a private repo... and only offered to selected individuals...
-
@admin This is an excellent idea to keep the repository private. If made public, Netflix could check what you're doing and easily block everything.
-
this is what we were thinking... currently we are only offering this to particular users of our RapidAPI
-
How far into the 'gathering of data' do you have to go to tell what resolutions of video are available for a particular title? I have a selenium based 'searcher for netflix' but would like to possibly take it more along the lines of what you guys do, but not sure if you can determine the resolutions, or do you actually have to go as far as trying to watch the video before you get that info?
-
They do have what resolutions are available in each country but it is a bit inconsistent...